Daily Trend [10-25]
【1】TACo: Token-aware Cascade Contrastive Learning for Video-Text Alignment
【URL】http://arxiv.org/abs/2108.09980
【Time】2021-08-23
一、研究领域
对比学习,video-text对齐,多模态表示学习
二、研究动机
改进大规模预训练和下游特定任务的视频文本对齐
三、方法与技术
Framework 的三个组件:
(1)Video encoding module:先使用一些预训练的模型提取 input video 的特征,然后 Video Encoder 负责通过self attention处理这些 embedings ,得到 m 个 d 维视频特征(m是采样的帧数)
(2)Language encoding module:使用一些预训练的 tokenizer 和 BERT 对文本 token 化并提取 input text 的特征(句子开头和结尾会加[CLS]和[SEP]),然后由 Language Encoder 负责投影得到n个d维文本特征(注意保持 video 和 text Encoder 的输出维度相同为d)
(3)Multi-modal fusion module:它的输入是 video feature (md) 和 text feature (nd) ,输出是融合后的 feature ((m+n)*d)。在这个过程中,为了帮助它区分视频和语言token,使用标记类型嵌入层来学习两个嵌入,并将它们分别加到视觉和文本标记中。
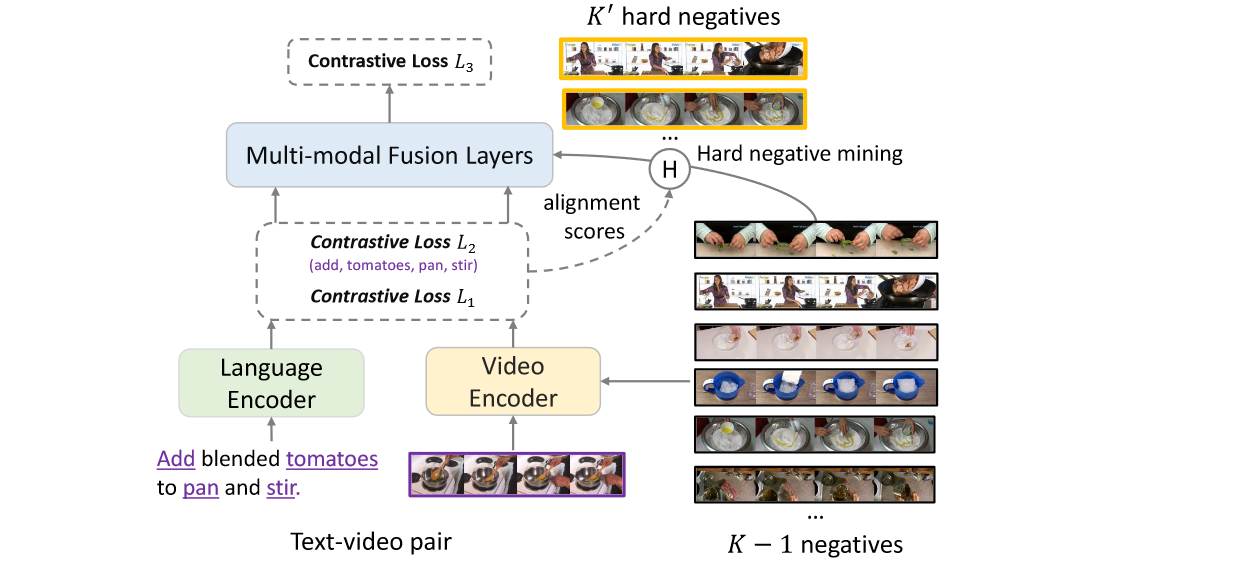
计算三个对比损失:
1)所有反例的句子级损失 L1;
2)所有反例的实词(名词、动词)的tokenlevel损失L2;
3)基于L1和L2在线采样的硬负例的句子级损失L3。
四、总结
旨在解决当前对比学习流程中存在的两个问题:缺少细粒度对齐和多模态融合采样效率低下。
http://y-ichen.github.io/2023/10/25/2023-10-25%20[Daily%20Trend]%20c3f17d22438a4bfaa23d09964da359f4/
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.